4/13 (土) 羽村堰に立ち寄って、奥多摩までのぼってきた

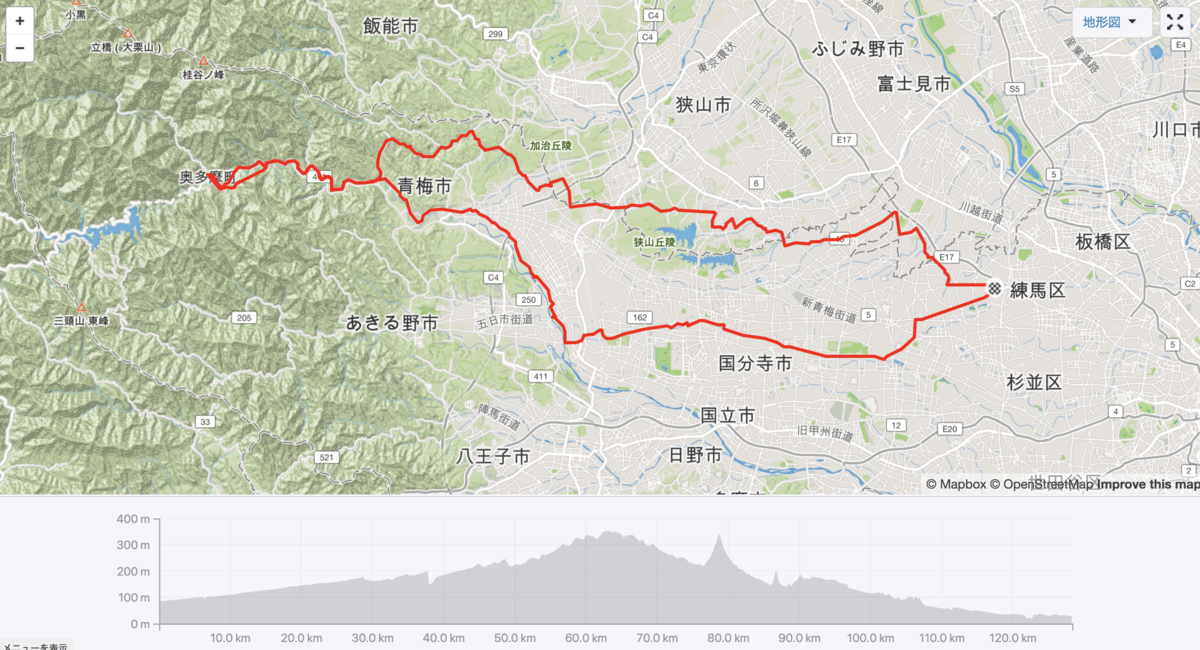
都内では桜の満開を過ぎてしまい、西部の山中の桜がこれから満開を迎えるという頃合いだった。奥多摩湖の桜を見るつもりで出かけたが帰りが遅くなりそうだったので途中で下山して終わり. 128km で finish
続きを読む表題の通り CVE-2019-9857 が出ており、その PoC を書いてどのような影響があるのを検証・観察した.
In the Linux kernel through 5.0.2, the function inotify_update_existing_watch() in fs/notify/inotify/inotify_user.c neglects to call fsnotify_put_mark() with IN_MASK_CREATE after fsnotify_find_mark(), which will cause a memory leak (aka refcount leak). Finally, this will cause a denial of service.
ローカルの攻撃者により inotify でDoS を引き起こせる 脆弱性です.
続きを読む前回の続きです
本エントリでは ProcDump が コアダンプをどのように採取するかを調べていく.
(現状の) Linux ProcDump は gcore を薄くラップして扱うバイナリと理解した
ソースコードの量は大したことないので git clone してざっと斜め読みするといい. スレッドを積極的に使う設計は Windows な流儀なのかな?
ファイルの量も少ないの順番に眺めていって、CoreDumpWriter.c がコアダンプ採取の責務を負っているソースだと判別をつけた.
詳細はすっ飛ばして、以下の行を見れば gcore を popen2() で呼び出しているのが確認できる
int WriteCoreDumpInternal(struct CoreDumpWriter *self) { // ... // assemble the command if(sprintf(command, "gcore -o %s_%s_%s %d 2>&1", name, desc, date, pid) < 0){ Log(error, INTERNAL_ERROR); Trace("WriteCoreDumpInternal: failed sprintf gcore command"); exit(-1); } // generate core dump for given process commandPipe = popen2(command, "r", &gcorePid); self->Config->gcorePid = gcorePid;
popen2 はシェルを fork(2) して pipe(2) で結果を受け取る関数である. Python や Ruby のインタフェースを真似た感じかな? (この関数の実装も同ファイルに載っているが、冗長なので省略する)
gcore の中身はシェルスクリプトで、 gdb をラップしたコマンドである. gdb をインストールすると付属してくるコマンド
gcore を呼び出すと、結局は gdb を呼びだすことになる. ProcDump 独自の実装でコアダンプを採取しているのかと思ったが、そんなことなかった 🙃 すでに gdb で出来ることを作り直すのは、大車輪の再実装になるもんね
前回のエントリでは CPU 使用率やメモリ(RSS) を閾値にしてコアダンプをとってみたが、どういった仕組みなのだろうか?

ProcDump プロセスを strace すると /proc/$pid/stats を 1秒ごとに open(2), read(2) しているスレッドがトレースできる
# 💤 1秒ブロックすることを示す
[pid 3073] futex(0x60b5bc, FUTEX_WAIT_BITSET_PRIVATE|FUTEX_CLOCK_REALTIME, 25, {1550324077, 477259191}, ffffffff) = -1 ETIMEDOUT (Connection timed out) 💤
[pid 3073] futex(0x60b590, FUTEX_WAKE_PRIVATE, 1) = 0
[pid 3073] kill(3060, SIG_0) = 0
[pid 3073] open("/proc/3060/stat", O_RDONLY) = 3 👈
[pid 3073] fstat(3, {st_mode=S_IFREG|0444, st_size=0, ...}) = 0
[pid 3073] read(3, "3060 (a.out) S 2854 3060 2854 34"..., 1024) = 301
[pid 3073] close(3) = 0
[pid 3073] kill(3060, SIG_0) = 0
[pid 3073] futex(0x60b5bc, FUTEX_WAIT_BITSET_PRIVATE|FUTEX_CLOCK_REALTIME, 27, {1550324078, 479654480}, ffffffff) = -1 ETIMEDOUT (Connection timed out) 💤
[pid 3073] futex(0x60b590, FUTEX_WAKE_PRIVATE, 1) = 0
[pid 3073] kill(3060, SIG_0) = 0
[pid 3073] open("/proc/3060/stat", O_RDONLY) = 3 👈
[pid 3073] fstat(3, {st_mode=S_IFREG|0444, st_size=0, ...}) = 0
[pid 3073] read(3, "3060 (a.out) S 2854 3060 2854 34"..., 1024) = 301
[pid 3073] close(3) = 0
[pid 3073] kill(3060, SIG_0) = 0
[pid 3073] futex(0x60b5bc, FUTEX_WAIT_BITSET_PRIVATE|FUTEX_CLOCK_REALTIME, 29, {1550324079, 503662811}, ffffffff) = -1 ETIMEDOUT (Connection timed out) 💤
[pid 3073] futex(0x60b590, FUTEX_WAKE_PRIVATE, 1) = 0
[pid 3073] kill(3060, SIG_0) = 0
[pid 3073] open("/proc/3060/stat", O_RDONLY) = 3 👈
[pid 3073] fstat(3, {st_mode=S_IFREG|0444, st_size=0, ...}) = 0
[pid 3073] read(3, "3060 (a.out) S 2854 3060 2854 34"..., 1024) = 301
[pid 3073] close(3) = 0
[pid 3073] kill(3060, SIG_0) = 0
ここらの実装は TriggerThreadProcs.c に書いてある
初見で「phtread を抽象化して扱ってるし、難しいのかな ...? 」と身構えてしまったが、詳細を読んでいくと思ったよりも素朴な実装 + 設計である.
/proc/$pid/stat や cgroup の値を閾値 最新のメトリクスだと PSI なんかを見張ったりすると、より精緻なトリガーを作れたりするのかなと思った
コアダンプ採取のコードは gcore だった
gstack に置き換えられるといいかなぁ先のエントリで書いたように最近は Windows も触っていて 主に Sysinternals ツールを使って Windows 探検をしている
その流れで ProcDump の使い方を調べていた.

Windows 版の詳細は上記のリンクを辿って自分でご覧になって欲しい。その中で、CPU 使用率やメモリ使用量(コミットチャージ) をコアダンプ生成のトリガーにできるのが目に留まった
-c
CPU しきい値を指定します。このしきい値に達すると、プロセスのダンプが作成されます。
-m
メモリ コミットのしきい値を MB 単位で指定します。このしきい値に達すると、プロセスのダンプが作成されます。
gdb もこんな風に扱えたら便利かな〜??? と思っていたところ、ふと Linux 版の存在があるのを思い出したのだった!
下記のリポジトリで ProcDump の Linux 版が公開されている
ディストリビューション向けのパッケージが配布されており、インストールの手順はREADME.md に書かれている
手順通りに Ubuntu Xenial にインストールして、man を読み何ができるのかをざっと調べる
man(8) procdump manpage man(8) NAME procdump - generate coredumps based off performance triggers. SYNOPSIS procdump [OPTIONS...] TARGET -C CPU threshold at which to create a coredump of the process from 0 to 100 * nCPU -c CPU threshold below which to create a coredump of the process from 0 to 100 * nCPU -M Memory commit threshold in MB at which to create a coredump -m Trigger when memory commit drops below specified MB value -n Number of dumps to write before exiting -s Consecutive seconds before dump is written (default is 10) TARGET must be exactly one of these: -p pid of the process DESCRIPTION procdump is a Linux reimagining of the class ProcDump tool from the Sysinternals suite of tools for Windows. Procdump provides a convenient way for Linux developers to create core dumps of their application based on performance triggers. 1.0.1 12/18/2017 man(8)
Linux 版でも CPU使用率 やメモリ使用量をトリガーにしてコアダンプできる。コアダンプを採取する回数を指定できたり、採取の間隔を指定できる
アーキテクチャに依存しないエッセンスとなるオプションだけを実装した感じで、Windows 版よりだいぶ簡素かな?
以下のようなテストプロセスを起動して、ProcDump でコアダンプを採取する
さて、上記のプロセスを ProcDump したのを GIF 動画でにした
コアダンプが合計3回採取されているのがわかるだろうか?
上記のデモで使ったソースは下記の通り
#include <stdio.h> #include <stdlib.h> #include <unistd.h> void malloc_and_free() { size_t size = 100 * 1024 * 1024; char *p = malloc(size); if (p == NULL) { perror("failed to malloc"); exit(1); } // memset でもええねん for (size_t i = 0; i < size; i++) { p[i] = '@'; } sleep(3); free(p); } int main() { sleep(5); malloc_and_free(); malloc_and_free(); malloc_and_free(); }
注意: ProcDump の動作を確認するためのコードなので、コアダンプを採取しても面白いことはなにもない
CPU 使用率を監視してダンプを採取する GIF 動画が ProcDump のリポジトリにのっているので、引用として掲載する

Source: GitHub - microsoft/ProcDump-for-Linux: A Linux version of the ProcDump Sysinternals tool
採取したコアダンプを調査することで CPU 使用率が高い時のバックトレースを調べていくことができるだろう
網を張って気長に待つようなデバッグに向いてるだろう
長時間実行した際に特定の負荷のパターンでうごくプロセスがいるとして、そのようなケースで作業を半自動化できて便利だろう. ( 例: たまーに CPU時間が10数秒スパイクするプロセスがいて調査したいが、再現するタイミングがよくわからない )
『Windows Sysinternals徹底解説 改訂新版』でもそのようなトラブルシューティングの例を出している
次回のエントリでは Procump の実装を見ていく
会社 で Windows Surface Go を支給してもらったので Windows 筋トレをしている
腰を据えて Windows を触るのは WIndows XP を扱って以来で 10数年ぶり (2011年位に会社から 1-2ヶ月間だけ貸与してもらったことはあるけど).

Surface Go を手に入れるまではコントロールパネルを開く方法も分からないくらいに退化していた
ということで『インサイド Windows 第七版』と『Windows Sysinternals 徹底解説』を買った
")
インサイドWindows 第7版 上 システムアーキテクチャ、プロセス、スレッド、メモリ管理、他 (マイクロソフト公式解説書)
")
Windows Sysinternals徹底解説 改訂新版 (マイクロソフト公式解説書)
低レイヤーの話が高密度で書き記されているが、Linux カーネルの問題に取り組んできた際に身につけた知識や経験も手伝って「Windows っておもろい OS 」なんだなと、たくさんの発見をしながら読みすすめられている.
Linux と同じように捉えていいモデルや概念や設計があれば、全く異種や未知のものもあり、Windows のことをほんと表層的にしか理解できてなかったのだと痛感している.
VMMap でプロセスのメモリレイアウトを見るとこんなんになる

VMMap を使うと Linux の pmap と 似た出力 を得られる.
似た と書いたが、プロセスのメモリレイアウトは CPU (x86アーキテクチャ) を反映している / 密結合するポイントのせいか、Windows と Linux とで大きくは変わらないようだ. フィールド名の差異はあれど pmap の出力を理解してれば VMMap も難なく理解できる (その逆も然りだろう).
Process Explorer でプロセス一覧をみる

プロセスモデルは抽象化のアプローチが Linux とは全然違うもんなんだな〜 と素朴な感想を持っている. ハードから離れたレイヤでの抽象化は OS の個性が輝くところなのだろう
このように Windows の本を読みながら Linux と比較しながら進めている.
ここからは全く別の話題
技術の勉強に励む際に 入門書を手にしてボトムアップで固めて攻めていくのは一つの勉強手段だ. 別の手段として、いろいろレベル感をすっ飛ばした書籍にチャレンジしてトップダウンで進める方法あるだろう. unknown-unknown の森に飛び込み known-unknown の中で迷子になりながら鍛えていく方法.
その中でknown unknownという概念が紹介されている。それは、システムチューニングの局面においてknown-known,known-unknown,unknown-unknownという分類で説明されている。
さらに引用
known-knownは知っていることを知っていること、例えばtopコマンドでプロセスごとのCPUの使用率を見れることを知っているし、見たことがある。 known-unknownは知らないことを知っていること。topコマンドを知っているけど、使ったことはない(観測してない) unknown-unknownは知らないことを知らないこと。これはtopコマンドを知らないこと。
もう一個引用
これを少しでもknown-unknownにするためにはひたすら本を読むとか、識者に教えてもらうとか、インターネットで調べるとかそういう手段になると思うのだけど (...)
自分の過去を振り返るならば、『詳細 Linux カーネル』を手にしたのは 10年も前のことだが、書籍を買った当初はどこを読んでもまったくもって何も理解ができずに圧倒されてしまった.

known-unknown の山 (鈍器) がそこに (物理的に) 存在することは確実に理解はした. ( なんで買ったんだこの本??? )
そもそも C言語を全く書けないのにカーネル本を手にしたのがすっ飛ばし過ぎてるようにも思い、ゆっくりと時間をかけて、C言語の入門書を読んだり、『詳解 UNIX プログラミング』にチャレンジしたり、途中で全く興味を失ったり、何かの機会に興味が再発したり、また飽きたり ... と紆余曲折を経ながらも少しずつ known-unknown を known-known に変えることができた.
現在では 会社のお仕事の場面でも知識 + 経験 + スキルとして生かせるレベルまで書籍の内容を吸収したと思う ( 未だコードは全然かけないけど 🙃 )
このように過去の話をふりかえるとバイアスが強烈にかかり、美化して話がちだ.
失敗している例もあって、技術的に理解が及ばないまま背伸びして買った書籍で内容を全然モノにしないまま挫折したのもたくさんある. 私はグラフィカルなレイヤを扱うのはどうも苦手で、そういったレイヤの技術書はどれもこれも途中で放り投げてしまった ( 懐かしの ActionScript3 や Processing や iOSアプリや ... )
何の技術がどうやって自分の強み・興味・自信のコアとして定着するかは、短い時間の中では推し量れないもんだね


